


How much uptime can I afford?
99.5% uptime is more cost-effective than 99.99% for most startups!

Software engineers love working on nice juicy problems, especially ones that are rich in CV-worthy buzzwords. It is a rare engineer that will admit:
💡 Engineering for 99.5% uptime is more cost-effective than 99.99% for most startups!
"But why shouldn’t my engineers strive for excellence?"
Of course they should, but 99.99% guaranteed uptime cannot be achieved merely by doing things perfectly. For that level of reliability, your engineers need to do things differently. You'll need specialised architecture, redundant infrastructure, and streamlined operational and organisational procedures.
It's unlikely to be cost-effective, unless you do the calculations and prove to yourself that your case warrants it. Most businesses do not need 99.999% ("five-nines") uptime, or even 99.99% ("four-nines"). 99.5% ("two-and-a-half nines") uptime is very decent.
What's the big deal?
💡 A system with 99.99% guaranteed uptime must be 50 times(!) as reliable as one with "only" 99.5%.
This is easier to see when you compare the amount of downtime allowed: 0.01% vs. 0.50%.
How much does this cost?
The cost of building and operating a system in a way that guarantees 99.99% uptime is several times as expensive as 99.5%. This is in terms of system complexity, the number of engineers required, their specialisations, experience levels, and corresponding salaries, as well as significantly increased operational costs and arrangements.

What level of reliability should I aim for?
It's a business decision, not a technical one. Evaluate the effect of downtime on the business before even starting to discuss the technical implications.
How much does an hour of downtime cost you?
Ask yourself these questions:
If you have an e-commerce platform, how much revenue (or dare I say it, profit) does it make per hour?
How much downtime can your customers tolerate?
How much damage will an hour of downtime do? This can be both due to direct loss of revenue and also due to eventual customer churn due to loss of trust.
Bonus question: are all hours of downtime equal, or are some hours less costly, such as weekends or after midnight?
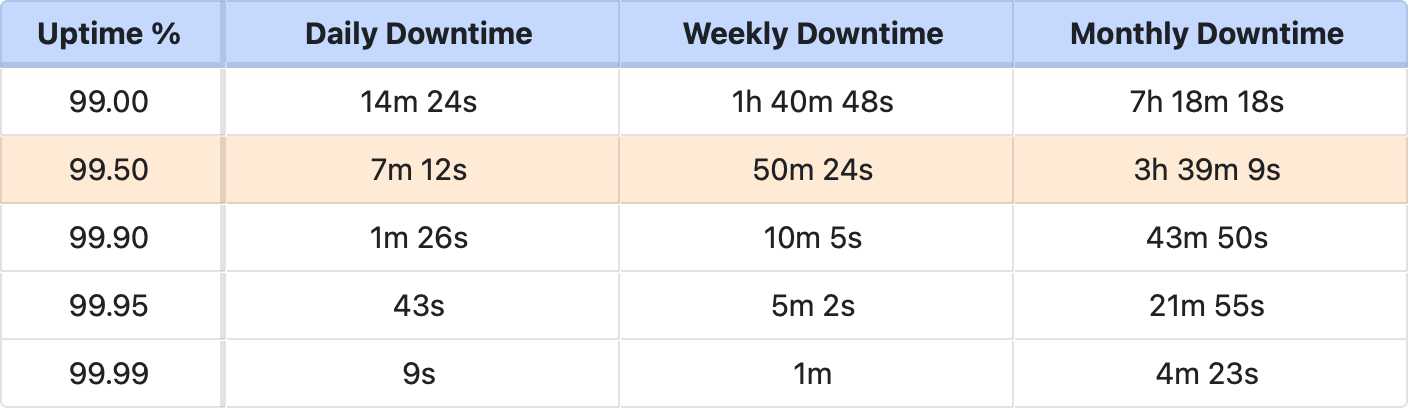
How much downtime can you tolerate?
These are the total downtimes you can expect for corresponding uptime guarantees:
Operational & Organisational Aspects
The limitations on your uptime are most likely operational, not technical. You typically have a higher risk of downtime due to operational issues than due to technical problems. There may be fewer things that can go wrong, but when they do, it takes many hours to fix them.
Let's assume that a system — engineered for 99.99% guaranteed uptime — dropped from the sky into your lap. On a technological level, such a system will have redundancies to ensure that there are no single points of failure. However, single points of failure do not have to be technical; they can also be administrative.
💡 A credit card can be a single point of failure.
I have seen operational accounts frozen because a credit card went over its spending limit. How many hours will it take for you to first notice that there's a serious problem, identify that the cause is not technical, and then actually rectify it? A single such event will destroy your 99.99% uptime record.
Are you organised to prevent such "unplanned administrative downtime"? It's not trivial, because you need to have cross-departmental plans and procedures both to prevent, and to handle such events.
Do you have a 24x7 rota of engineers?
Do you have monitoring and alerting that will activate your 24x7 support when an error rate threshold is crossed?
Scheduled downtime for maintenance is an additional operational point to consider. Do you allow this at all? If you do, should it fit within the downtime parameters you allow yourself? What are the risks of it lasting longer than planned? The solution may be technical, but the decision is a business one.
Infrastructure & SaaS Provider Guarantees
"The infrastructure I use guarantees 99.xx% uptime."
Let's unpack this sentence. Consider Amazon Web Services (AWS), for example.
Redundancy — Amazon's Service Level Agreement ("SLA") for EC2 specifies 99.5% uptime for a single machine instance. By running multiple redundant machines you can increase this, but what if the EC2 failure affects multiple machines?
Availability zones = better redundancy — The answer is to have a redundant system running in at least one other "availability zone". Each zone is geographically separated, has an independent power supply, independent internet connection etc. Running two machines, one in each of two such independent availability zones, allows you to multiply the probabilities and get 99.75% uptime. In reality, Amazon's SLA actually specifies 99.99% for this combination.1
Downtime is cumulative across services — You'll use multiple different AWS services (e.g. EC2, ELB, S3, CloudFront). Each service's SLA specifies its own uptime. The downtime is cumulative from a probability standpoint. This means that even if you use four services, each having a 99.99% uptime SLA, you'll have a common uptime expectation of 99.96%.2 This is not "almost 99.99%" — it gives 4 times as much downtime! Therefore, if you are using multiple services, your cloud provider's uptime SLA for any one service should be considered to be an upper limit for your whole system.
What "guarantee" means to you vs. cloud providers
In addition to the back-of-the-envelope maths above, we need to consider what is meant by the term "guarantee". You probably will not find this word in any service level agreement. Cloud providers promise to make "commercially reasonable efforts" to make their services available with a specified uptime percentage. If they don't meet this in a specific month, they agree (typically upon your explicit request) to deduct a pro-rated amount from your bill, corresponding to the duration of the outage or a fixed percentage based on the actual range of uptime they delivered. The cloud providers do not reimburse you for your actual losses.3 So based on your monthly spend, how much is a cloud provider's 99.99% SLA worth to you?
Other providers in your SaaS supply chain
Do you have other providers in your supply chain, such as GitHub, npm, and CircleCI? They might not be critical for production, but any problems there can delay deployment of a fix to production.
Your own code must meet your uptime requirements too!
Your own code runs on top of the infrastructure we discussed above. If you are aiming for 99.99%, your own code has to be part of this. Is your own QA and load testing thorough enough to guarantee 99.99% uptime of your own code, even without considering the reliability of the infrastructure layer?
Wrapping Up
99.5% uptime is reasonably achievable without excessive costs and distractions. Anything more costs a lot more.
The good news is that if your own system is constructed well, your actual uptime will likely be significantly better than this, because the providers try to do better than what they promise. It's the guarantee that's expensive, not the typical result.
Each layer of your system needs to have a higher reliability, in isolation, than the final uptime you're aiming for, because error rates are cumulative.
Before spending a lot of money, time, and resources on development, upgrade your operational capabilities and administrative procedures.
If any individual measures (e.g. 24x7x365 on-call support) are not achievable, that doesn't mean you should give up. Do the best with what you can afford.
Hopefully you have gained a fresh perspective that will help you decide what you really need, and be conscious of where your real risks are.
This would seem to indicate that internally they aim for higher reliability than they promise in their SLA.
It's actually less than that for one availability zone, because the services are not independent.
There's insurance for that; "downtime insurance" is a thing, apparently.